llm-api.arc.vt.edu
Description
https://llm-api.arc.vt.edu/api/v1/ provides OpenAI and Anthropic compatible API endpoints to a selection of LLMs hosted and run by ARC. It is based on the Open WebUI platform, and integrates several inference and integration capabilities, including retrieval-augmented generation (RAG), web search, vision, and image generation.
Access
All Virginia Tech students, faculty, and staff may access the service at
https://llm-api.arc.vt.edu/api/v1/using a personal API key. No separate ARC account is required to use the API.There is no charge to individual users for accessing the hosted models via the API.
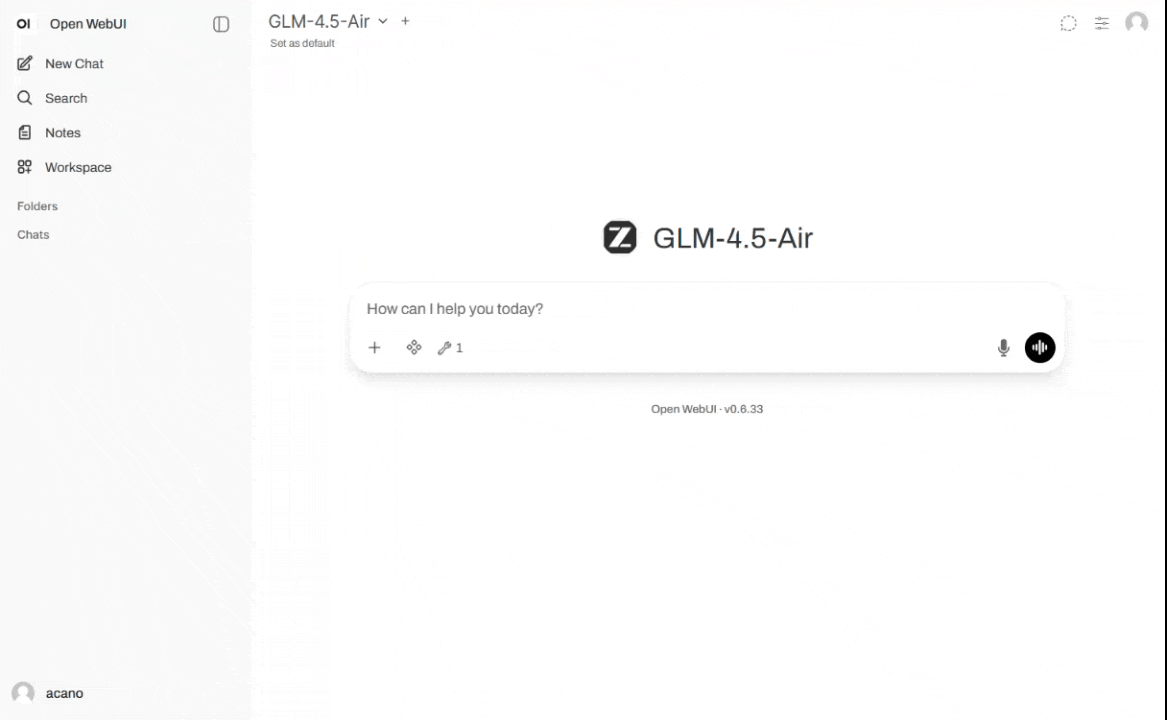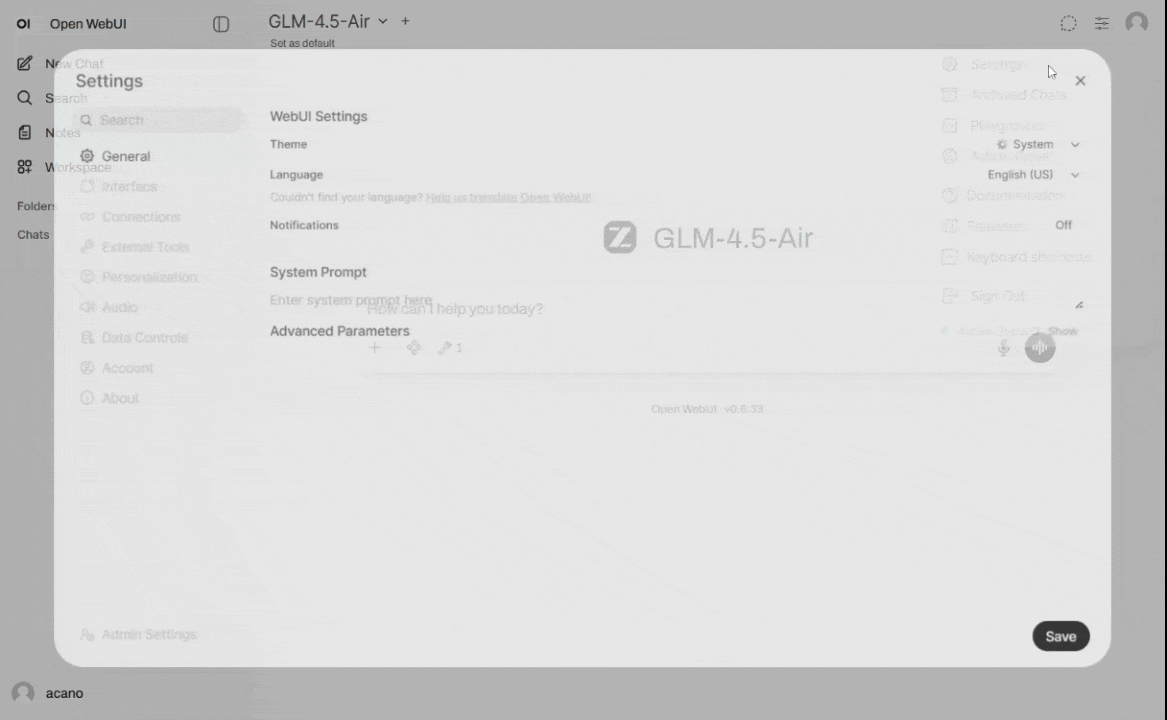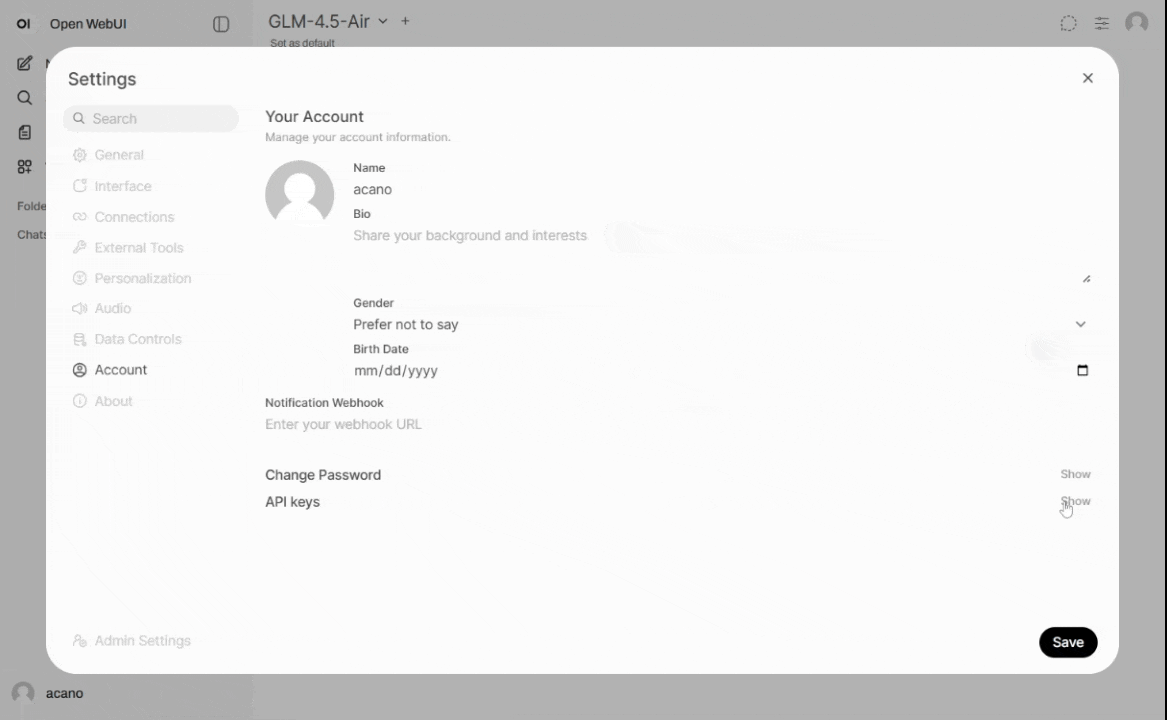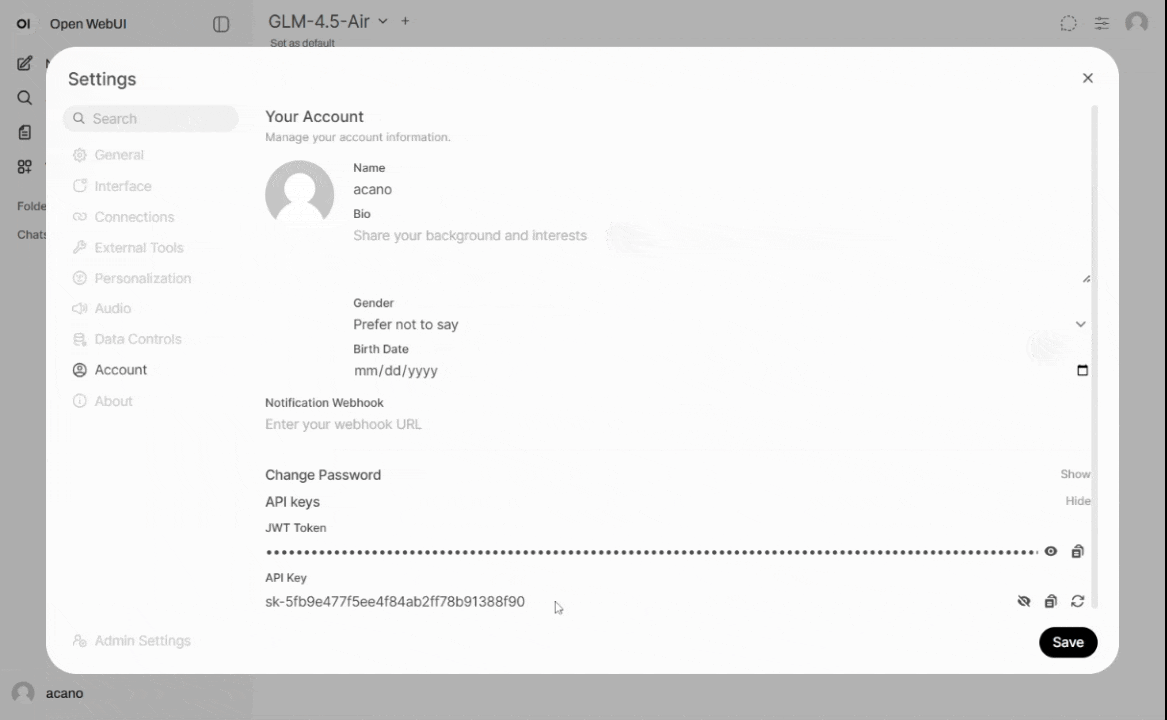
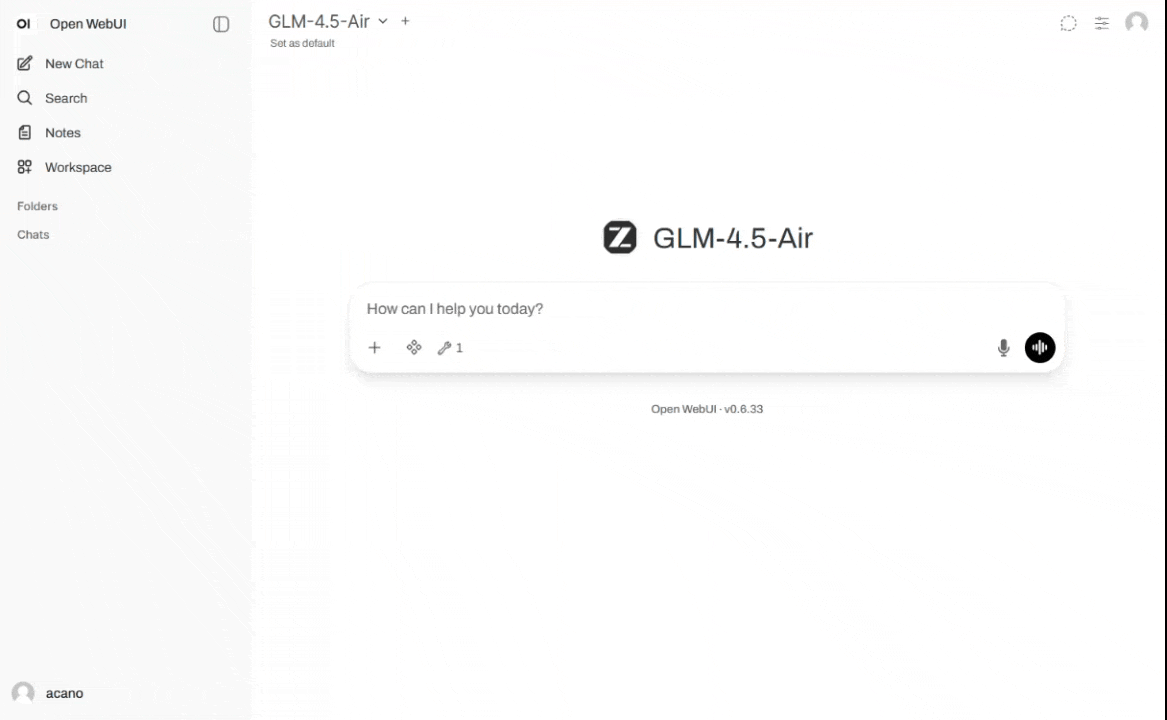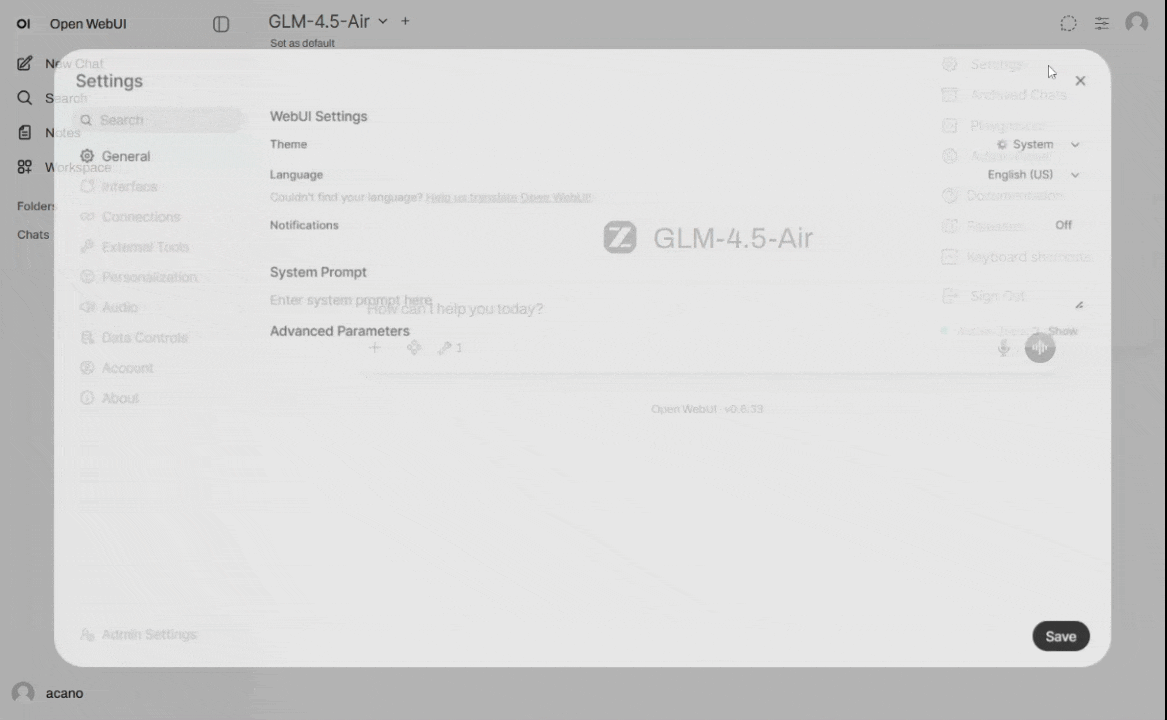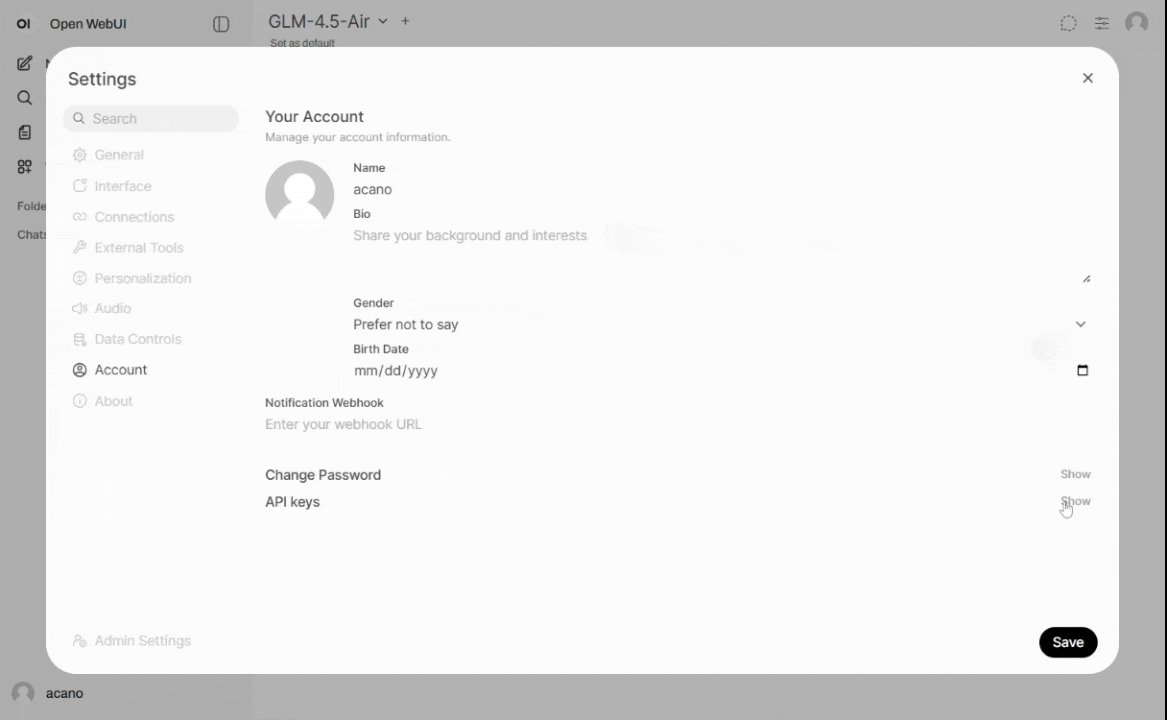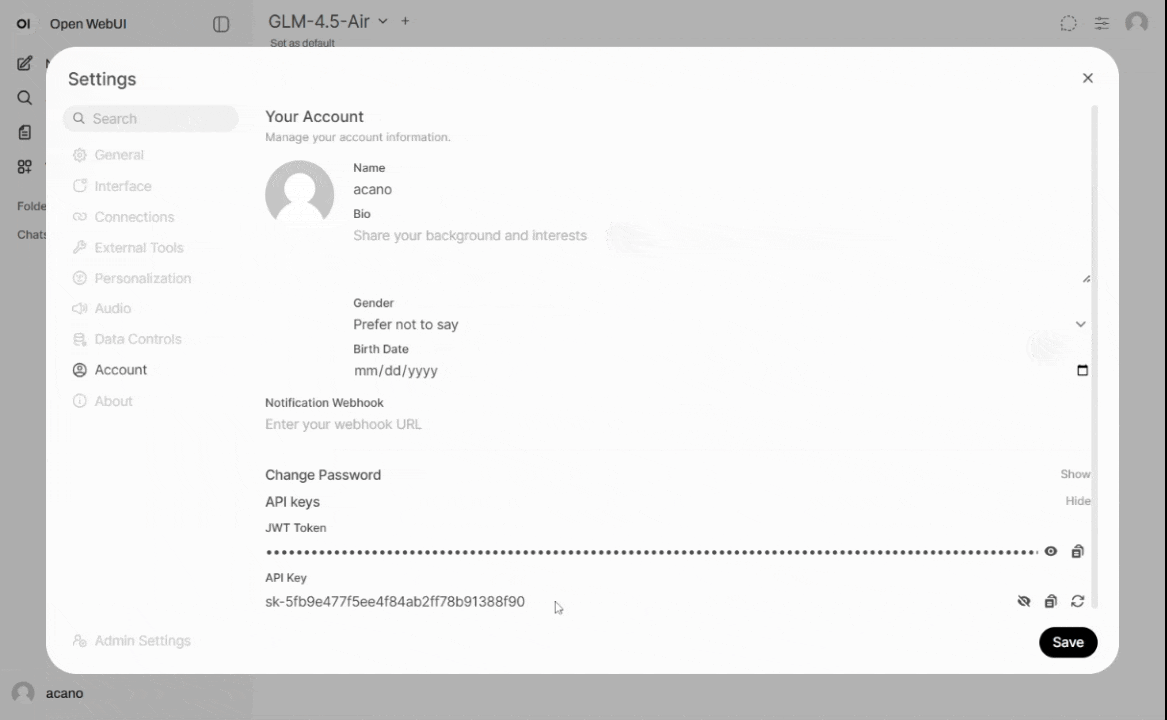
Users must generate an API key through https://llm.arc.vt.edu
User profile > Settings > Account > API keys. Keys are unique to each user and must be kept confidential.
Caution
Sharing API keys with other users is strictly prohibited. Any unauthorized use of shared credentials will be reported to the IT Security Office and access will be terminated.
Restrictions
Data classification: Researchers can use this tool for high-risk data. This service is approved by VT Information Technology Security Office (ITSO) for processing sensitive or regulated data. However, researchers are reminded to consult with VT Privacy and Research Data Protection Program (PRDP) and the Office of Export and Secure Research Compliance regarding the storage and analysis of high-risk data to comply with specific regulations. Note that some high-risk data (e.g. data regulated by DFARS, ITAR, etc.) require additional protections and the LLM might not be approved for use with those data types.
Usage limits
Users are subject to API and web interface limits to ensure fair usage:
Limit |
Value |
|---|---|
Requests per minute |
30 |
Requests per hour |
1,000 |
Requests per 3-hour sliding window |
3,000 |
Max concurrent requests |
10 |
Max tokens per non-streaming request |
8,000 |
We ask power users to pace their requests and stay within these limits.
Note
If these limits are too restrictive for your workload, see the vLLM, Llama.cpp, or Open OnDemand LLM app documentation for self-hosted alternatives on ARC’s HPC clusters.
Models
ARC currently runs several state-of-the-art models. ARC will add or remove models and scale instances dynamically to respond to user demand. You may select your preferred model in the request settings, e.g. "model": "gpt-oss-120b".
OpenAI
gpt-oss-120b(see model card on Hugging Face). OpenAI’s flagship public model, best for fast responses.Z.AI GLM 5.2
GLM-5.2(see model card on Hugging Face). Top-performing model, best for complex tasks and coding.Moonshot AI
Kimi-K2.6(see model card on Hugging Face). Top-performing model, best for complex tasks and multimodal. Use for image creation, edition, and analysis. Defaultthinking_token_budget: 4000.MiniMaxAI
MiniMax-M2.7(see model card on Hugging Face). It is optimized specifically for software engineering tasks.
Models also offer pre-configured versions with different levels of thinking modes. You may use:
gpt-oss-120b— default configuration withreasoning_effort: mediumgpt-oss-120b-thinking-low— OpenAIgpt-oss-120bwithreasoning_effort: lowgpt-oss-120b-thinking-high— OpenAIgpt-oss-120bwithreasoning_effort: highGLM-5.2— default configuration withreasoning_effort: maxGLM-5.2-thinking-high— Z.AIGLM-5.2withreasoning_effort: highGLM-5.2-non-thinking— Z.AIGLM-5.2withenable_thinking: falseKimi-K2.6— default configuration withthinking_token_budget: 4000Kimi-K2.6-non-thinking— Moonshot AIKimi-K2.6withthinking: falseKimi-K2.6-thinking-low— Moonshot AIKimi-K2.6withthinking_token_budget: 1000Kimi-K2.6-thinking-high— Moonshot AIKimi-K2.6withthinking_token_budget: 8000MiniMax-M2.7— default configuration
Security
This service is hosted entirely on-premises within the ARC infrastructure. No data is sent to any third party outside of the university. All user interactions are logged and preserved in compliance with VT IT Security Office Data Protection policies.
Disclaimer
ARC has implemented safeguards to mitigate the risk of generating unlawful, harmful, or otherwise inappropriate content. Despite these measures, LLMs may still produce inaccurate, misleading, biased, or harmful information. Use of this service is undertaken entirely at the user’s own discretion and risk. The service is provided “as is”, and, to the fullest extent permitted by applicable law, ARC and VT expressly disclaim all warranties, whether express or implied, as well as any liability for damages, losses, or adverse consequences that may result from the use of, or reliance upon, the outputs generated by the models. By using this service, the user acknowledges and accepts these conditions, and agrees to comply with all applicable terms and conditions governing the use of the hosted models, associated software, and underlying platforms.
Examples
Please read the OpenAI API documentation for a comprehensive guide to understand the different ways to interact with the LLM. You may also consult the Open WebUI documentation for API endpoints for additional examples involving Retrieval Augmented Generation (RAG), knowledge collections, image generation, tool calling, web search, etc.
Shell API
Use this API to interact with the LLMs directly from the command line.
Chat completions
Submit a query to a model.
API_KEY="sk-YOUR-API-KEY"
curl -X POST "https://llm-api.arc.vt.edu/api/v1/chat/completions" \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-oss-120b",
"messages": [{
"role":"user",
"content":"Why is the sky blue?"
}]
}'
Document upload
Upload a document to the LLM. Every file is assigned a unique file id. You can use the file ids to do Retrieval Augmented Generation (RAG).
API_KEY="sk-YOUR-API-KEY"
curl -X POST \
-H "Authorization: Bearer $API_KEY" \
-H "Accept: application/json" \
-F "file=@/path/to/file.pdf" https://llm-api.arc.vt.edu/api/v1/files/
Retrieval Augmented Generation (RAG)
Upload a file, extract its file id, and submit a query about the document to the LLM.
API_KEY="sk-YOUR-API-KEY"
## Upload document and get file ID
file_id=$(curl -s -X POST \
-H "Authorization: Bearer $API_KEY" \
-H "Accept: application/json" \
-F "file=@document.pdf" \
https://llm-api.arc.vt.edu/api/v1/files/ | jq -r '.id')
## Use the file ID in the request
request=$(jq -n \
--arg model "gpt-oss-120b" \
--arg file_id "$file_id" \
--arg prompt "Create a summary of the document" \
'{
model: $model,
messages: [{role: "user", content: $prompt}],
files: [{type: "file", id: $file_id}]
}')
## Make the chat completion request with the file
curl -X POST "https://llm-api.arc.vt.edu/api/v1/chat/completions" \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d "$request"
Web search
Enable the server:websearch tool to let the model query online. This allows the model to decide if it wants to search for additional information online to provide a more accurate answer. You may encourage the model to use the web search by adding “Search on the web” to your prompt.
API_KEY="sk-YOUR-API-KEY"
curl -X POST "https://llm-api.arc.vt.edu/api/v1/chat/completions" \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-oss-120b",
"messages": [{
"role":"user",
"content":"Who is the US president right now? Search on the web"
}],
"tool_ids": ["server:websearch"]
}'
Reasoning effort
You may change the reasoning effort of gpt-oss-120b to (low, medium (default), high).
API_KEY="sk-YOUR-API-KEY"
curl -X POST "https://llm-api.arc.vt.edu/api/v1/chat/completions" \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d '{
"model": "gpt-oss-120b",
"messages": [{
"role":"user",
"content":"Why is the sky blue?"
}],
"reasoning_effort": "high"
}'
Image generation
This approach generates an image using Qwen/Qwen-Image-2512.
API_KEY="sk-YOUR-API-KEY"
OUTPUT="output.png"
RESPONSE=$(curl -s -X POST "https://llm-api.arc.vt.edu/api/v1/images/generations" \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d '{
"prompt": "Generate a picture of a white lab dog",
"size": "512x512"
}'
)
# Extract returned URL
FILE_URL=$(echo "$RESPONSE" | jq -r '.[0].url')
# Download image
curl -s -L -o "$OUTPUT" \
-H "Authorization: Bearer $API_KEY" \
"https://llm-api.arc.vt.edu$FILE_URL"
Image edition
This approach edits an image using Qwen/Qwen-Image-Edit-2511.
API_KEY="sk-YOUR-API-KEY"
INPUT="input.png"
OUTPUT="output.png"
# Encode input image
IMG_B64=$(base64 -w0 "$INPUT")
# Submit the image edit request
RESPONSE=$(curl -s -X POST "https://llm-api.arc.vt.edu/api/v1/images/edit" \
-H "Authorization: Bearer $API_KEY" \
-H "Content-Type: application/json" \
-d @- <<EOF
{
"image": "data:image/png;base64,$IMG_B64",
"prompt": "Change the color of the red blanket to blue"
}
EOF
)
# Extract returned URL
FILE_URL=$(echo "$RESPONSE" | jq -r '.[0].url')
# Download image
curl -s -L -o "$OUTPUT" \
-H "Authorization: Bearer $API_KEY" \
"https://llm-api.arc.vt.edu$FILE_URL"
Python API
Certain libraries are required for the API use in Python such as openai and requests. You may install them using pip:
pip install openai requests
Chat completions
Submit a query to a model.
from openai import OpenAI
import argparse
# Modify OpenAI's API key and API base to use the server.
openai_api_key = "sk-YOUR-API-KEY"
openai_api_base = "https://llm-api.arc.vt.edu/api/v1"
messages = [
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "What is Virginia Tech known for?"},
]
Document upload
Upload a document to the LLM. Every file is assigned a unique file id. You can use the file ids to do Retrieval Augmented Generation (RAG).
import os
import requests
api_key="sk-YOUR-API-KEY"
base_url="https://llm-api.arc.vt.edu/api/v1/files/"
file_path="document.pdf"
if os.path.isfile(file_path):
with open(file_path, "rb") as file:
response = requests.post(
base_url,
headers={
"Authorization": f"Bearer {api_key}",
"Accept": "application/json",
},
files={"file": file},
)
if response.status_code == 200:
print(f"Uploaded {file_path} successfully!")
else:
print(f"Failed to upload {file_path}. Status code: {response.status_code}")
else:
print(f"File not found")
Retrieval Augmented Generation (RAG)
Upload a file, extract its file id, and submit a query about the document to the LLM.
import os
import requests
import json
api_key="sk-YOUR-API-KEY"
file_path="document.pdf"
def upload_file(file_path):
if not os.path.isfile(file_path):
raise FileNotFoundError(f"File not found: {file_path}")
with open(file_path, "rb") as file:
response = requests.post(
"https://llm-api.arc.vt.edu/api/v1/files/",
headers={
"Authorization": f"Bearer {api_key}",
"Accept": "application/json",
},
files={"file": file},
)
if response.status_code == 200:
data = response.json()
file_id = data.get("id")
if file_id:
print(f"Uploaded {file_path} successfully! File ID: {file_id}")
return file_id
else:
raise RuntimeError("Upload succeeded but no file id returned.")
else:
raise RuntimeError(f"Failed to upload {file_path}. Status code: {response.status_code}")
file_id = upload_file(file_path)
url = "https://llm-api.arc.vt.edu/api/v1/chat/completions"
headers = {
"Authorization": f"Bearer {api_key}",
"Content-Type": "application/json"
}
data = {
"model": "gpt-oss-120b",
"messages": [{
"role": "user",
"content": "Create a summary of the document"}],
"files": [{"type": "file", "id": file_id}],
}
response = requests.post(url, headers=headers, data=json.dumps(data))
print(response.text)
Image generation
This approach generates an image using Qwen/Qwen-Image-2512.
import base64
import requests
from urllib.parse import urlparse
from openai import OpenAI
openai_api_key = "sk-YOUR-API-KEY"
openai_api_base = "https://llm-api.arc.vt.edu/api/v1"
client = OpenAI(
api_key=openai_api_key,
base_url=openai_api_base,
)
response = client.images.generate(
prompt="A gray tabby cat hugging an otter with an orange scarf",
size="512x512",
)
base_url = urlparse(openai_api_base)
image_url = f"{base_url.scheme}://{base_url.netloc}" + response[0].url
headers = {"Authorization": f"Bearer {openai_api_key}"}
img_data = requests.get(image_url, headers=headers).content
with open("output.png", 'wb') as handler:
handler.write(img_data)
Image edition
This approach edits an image using Qwen/Qwen-Image-Edit-2511.
import base64
import json
import requests
from pathlib import Path
BASE_URL = "https://llm-api.arc.vt.edu/api/v1"
API_KEY = "sk-YOUR-API-KEY"
EDIT_INSTRUCTION = "Change the color of the orange scarf to blue."
INPUT_IMAGE = "input.png"
OUTPUT_IMAGE = "output.png"
def convert_image_to_base64(image_path: str) -> str:
image_path = Path(image_path)
if not image_path.exists():
raise FileNotFoundError(f"Image file not found: {image_path}")
return base64.b64encode(image_path.read_bytes()).decode("utf-8")
def request_image_edit(edit_instruction: str, image_path: str) -> list:
print("Submitting request for image edit...")
url = f"{BASE_URL}/images/edit"
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
}
image_b64 = convert_image_to_base64(image_path)
payload = {
"form_data": {
"prompt": edit_instruction,
"image": f"data:image/png;base64,{image_b64}"
},
}
resp = requests.post(url, headers=headers, json=payload, timeout=300)
resp.raise_for_status()
return resp.json() # <-- returns a LIST
def extract_file_url(result_list: list) -> str:
"""
The API returns: [ { "url": "/api/v1/files/.../content" } ]
"""
if not isinstance(result_list, list) or not result_list:
raise ValueError("Unexpected response: expected non-empty list")
entry = result_list[0]
if "url" not in entry:
raise ValueError(f"No URL found in response: {entry}")
return entry["url"]
def download_file_from_url(file_url: str, out_path: str) -> None:
headers = {"Authorization": f"Bearer {API_KEY}"}
# If URL is relative, prepend host
if file_url.startswith("/"):
file_url = BASE_URL + file_url.replace("/api/v1", "")
r = requests.get(file_url, headers=headers, timeout=60)
r.raise_for_status()
Path(out_path).write_bytes(r.content)
print(f"Saved edited image to {out_path}")
result = request_image_edit(EDIT_INSTRUCTION, INPUT_IMAGE)
file_url = extract_file_url(result)
download_file_from_url(file_url, OUTPUT_IMAGE)
Image to text Python API
import requests
import base64
from pathlib import Path
url = "https://llm-api.arc.vt.edu/api/v1/chat/completions"
openai_api_key = "sk-YOUR-API-KEY"
image_path = "bonnie.jpg"
def convert_image_to_base64(image_path: str) -> str:
image_path = Path(image_path)
if not image_path.exists():
raise FileNotFoundError(f"Image file not found: {image_path}")
with open(image_path, "rb") as img_file:
encoded = base64.b64encode(img_file.read()).decode("utf-8")
return encoded
headers = {
"Authorization": f"Bearer {openai_api_key}",
"Content-Type": "application/json"
}
image_b64 = convert_image_to_base64(image_path)
data = {
"model": "Kimi-K2.6",
"messages": [
{
"role": "user",
"content": [
{
"type": "text",
"text": "Describe the image"
},
{
"type": "image_url",
"image_url": {"url": f"data:image/jpeg;base64,{image_b64}"}
}
]
}
]
}
response = requests.post(url, headers=headers, json=data, timeout=30)
print(response.json()["choices"][0]["message"]["content"])
For repeated queries on the same image, see the reusable uploaded image workflow below.
Vision workflow with reusable uploaded images
For repeated vision queries on the same image, This workflow is supported where the image is uploaded once through /api/v1/files/ and then referenced by file ID in subsequent requests.
This differs from the inline base64 workflow, where the full image must be included in every request.
When to use this workflow
Use this approach when:
You need to run multiple prompts against the same image
You want to avoid repeatedly sending the same image in the request payload
For one-off vision requests, the inline base64 workflow might still be simpler.
Endpoint note: /api/v1 vs /api
ARC exposes two API styles that are used differently in this workflow:
/api/v1/...is the documented OpenAI-compatible path shown in the ARC examples/api/...is the native Open WebUI path. In this example,/api/chat/completionsis used for the file ID based vision request.
Follow the endpoint shown in the sample codes for the specific workflow you are using.
Example: upload an image once and reuse it by file ID
"""Upload an image once and reuse it in a vision request via VT ARC LLM API."""
import os
import requests
API_KEY = "sk-YOUR-API-KEY"
BASE = "https://llm-api.arc.vt.edu"
# 1. Upload the image
with open("input.png", "rb") as f:
upload_resp = requests.post(
f"{BASE}/api/v1/files/",
headers={"Authorization": f"Bearer {API_KEY}"},
files={"file": ("input.png", f)},
timeout=120,
)
upload_resp.raise_for_status()
file_id = upload_resp.json()["id"]
print(f"File ID: {file_id}")
# 2. Send chat completion referencing the file ID
# NOTE: use /api/chat/completions (not /api/v1/) — the native Open WebUI
# endpoint resolves bare file IDs to images server-side.
chat_resp = requests.post(
f"{BASE}/api/chat/completions",
headers={
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json",
},
json={
"model": "Kimi-K2.6",
"messages": [
{
"role": "user", "content": [
{"type": "text", "text": "Describe this image in detail."},
{"type": "image_url", "image_url": {"url": file_id}},
],
}
],
},
timeout=120,
)
chat_resp.raise_for_status()
resp = chat_resp.json()
print(resp["choices"][0]["message"]["content"])